
6.2 正则表达式语法规则
视频讲解:光盘TMlx602 正则表达式语法规则.mp4
一个完整的正则表达式由两部分构成,元字符和文本字符。元字符就是具有特殊含义的字符,如前面提到的“*”和“?”。文本字符就是普通的文本,如字母和数字等。PCRE风格的正则表达式一般都放置在定界符“/”中间。如“/w+([-+.']w+)*@w+([-.]w+)*.w+([-.]w+)*/”“/^http:// (www.)? .+.? $/”。为了便于读者理解,除了个别实例外,本节中的表达式不给出定界符“/”。
6.2.1 行定位符(^和$)
行定位符就是用来描述字串的边界。“^”表示行的开始;“$”表示行的结尾。如:
^tm
该表达式表示要匹配字串tm的开始位置是行头,如tm equal Tomorrow Moon就可以匹配,而Tomorrow Moon equal tm则不匹配。但如果使用
tm$
则后者可以匹配而前者不能匹配。如果要匹配的字串可以出现在字符串的任意部分,那么可以直接写成
tm
这样两个字符串就都可以匹配了。
6.2.2 单词分界符(b、B)
继续上面的实例,使用tm可以匹配在字符串中出现的任何位置。那么类似html、utmost中的tm也会被查找出来。但现在需要匹配的是单词tm,而不是单词的一部分。这时可以使用单词分界符“b”,表示要查找的字串为一个完整的单词。如:
btmb
还有一个大写的“B”,意思和“b”相反,它匹配的字串不能是一个完整的单词,而是其他单词或字串的一部分。如:
BtmB
说明
关于反斜线的用法,请参考6.2.10节。
6.2.3 字符类([ ])
正则表达式是区分大小写的,如果要忽略大小写可使用方括号表达式“[]”。只要匹配的字符出现在方括号内,即可表示匹配成功。但要注意:一个方括号只能匹配一个字符。例如,要匹配的字串tm不区分大小写,那么该表达式应该写作如下格式:
[Tt][Mm]
这样,即可匹配字串tm的所有写法。POSIX和PCRE都使用了一些预定义字符类,但表示方法略有不同。POSIX风格的预定义字符类如表6.1所示。
表6.1 POSIX预定义字符类
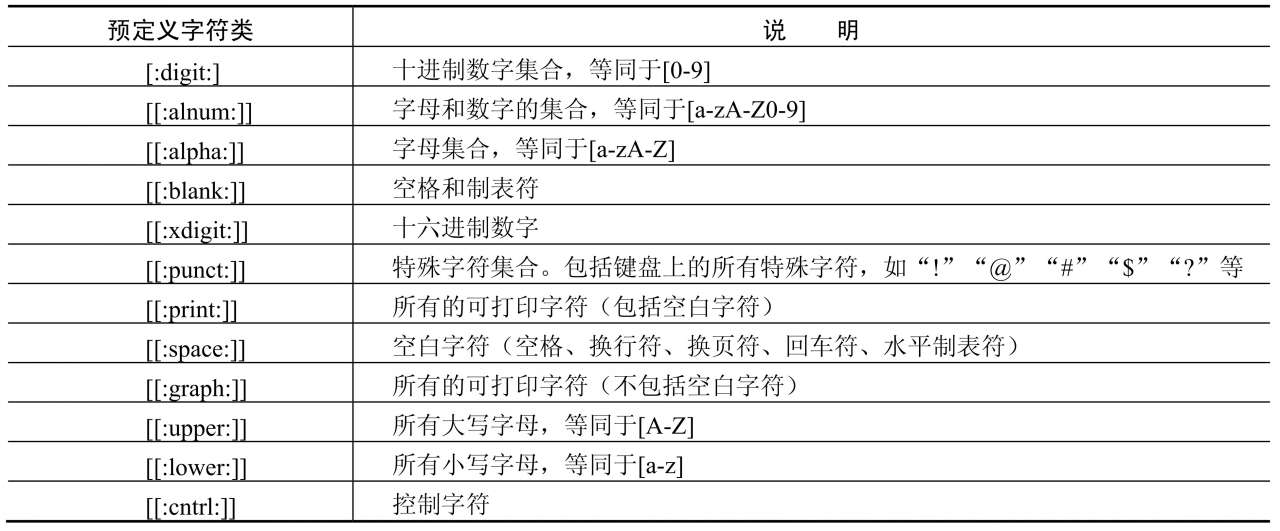
而PCRE的预定义字符类则使用反斜线来表示,请参考6.2.10节。
6.2.4 选择字符(|)
还有一种方法可以实现上面的匹配模式,就是使用选择字符(|)。该字符可以理解为“或”,如上例也可以写成
(T|t)(M|m)
该表达式的意思是以字母T或t开头,后面接一个字母M或m。
说明
使用“[]”和使用“|”的区别在于,“[]”只能匹配单个字符,而“|”可以匹配任意长度的字串。如果不怕麻烦,上例还可以写为
TM|tm|Tm|tM
6.2.5 连字符(-)
变量的命名规则是只能以字母和下划线开头。但这样一来,如果要使用正则表达式来匹配变量名的第一个字母,要写为
[a, b, c, d…A, B, C, D…]
这无疑是非常麻烦的,正则表达式提供了连字符“-”来解决这个问题。连字符可以表示字符的范围。如上例可以写成
[a-zA-Z]
6.2.6 排除字符([^])
上面的例子是匹配符合命名规则的变量。现在反过来,匹配不符合命名规则的变量,正则表达式提供了“^”字符。这个元字符在6.2.1节中出现过,表示行的开始。而这里将会放到方括号中,表示排除的意思。例如:
[^a-zA-Z]
该表达式匹配的就是不以字母和下划线开头的变量名。
6.2.7 限定符(? * + {n, m})
经常使用Google的用户可能会发现,在搜索结果页的下方,Google中间字母o的个数会随着搜索页的改变而改变。那么要匹配该字串的正则表达式该如何实现呢?
对于这类重复出现字母或字串,可以使用限定符来实现匹配。限定符主要有6种,如表6.2所示。
表6.2 限定符的说明和举例
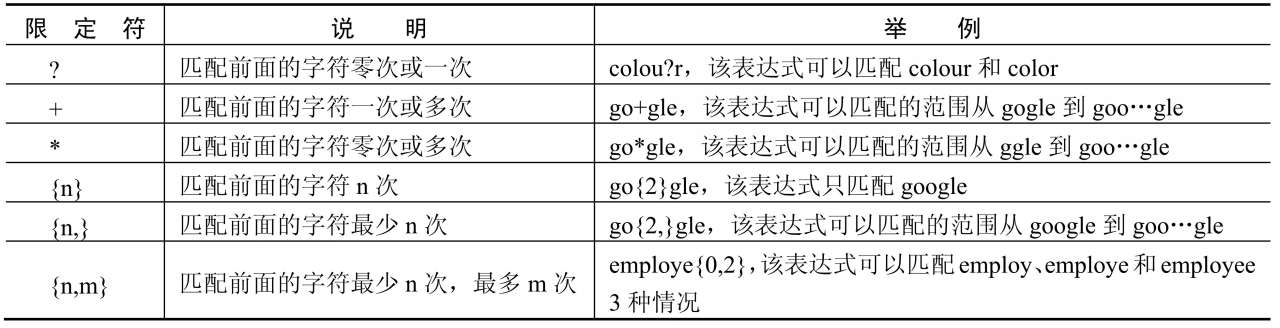
可以发现,在表6.2中实际已经对字符串进行了匹配,只是还不完善。通过观察发现,当Google搜索结果只有一页时,不显示Google标志,只有大于等于2时,才显示Google。说明字母o最少为两个,最多为20个,那么正则表达式为:
go{2,20}gle
6.2.8 点号字符(.)
如遇到这样的试题:写出5~10个以s开头、t结尾的单词,这是有很大难度的。如果考题并不告知第一个字母,而是中间任意一个。无疑难度会更大。
在正则表达式中可以通过点号字符(.)来实现这样的匹配。点号字符(.)可以匹配出换行符外的任意一个字符。注意:是除了换行符外的、任意的一个字符。如匹配以s开头、t结尾、中间包含一个字母的单词。格式如下:
^s.t$
匹配的单词包括sat、set、sit等。再举一个实例,匹配一个单词,它的第一个字母为r,第3个字母为s,最后一个字母为t。能匹配该单词的正则表达式为:
^r.s.*t$
6.2.9 转义字符()
正则表达式中的转义字符()和PHP中的大同小异,都是将特殊字符(如“.”“? ”“”等)变为普通的字符。举一个IP地址的实例,用正则表达式匹配诸如127.0.0.1这样格式的IP地址。如果直接使用点号字符,格式为:
[0-9]{1,3}(.[0-9]{1,3}){3}
这显然不对,因为“.”可以匹配任意一个字符。这时,不仅是127.0.0.1这样的IP,连127101011这样的字串也会被匹配出来。所以在使用“.”时,需要使用转义字符()。修改后上面的正则表达式格式为:
[0-9]{1,3}(.[0-9]{1,3}){3}
说明
括号在正则表达式中也算是一个元字符,关于括号的作用请参考6.2.11节。
6.2.10 反斜线()
除了可以做转义字符外,反斜线还有其他一些功能。
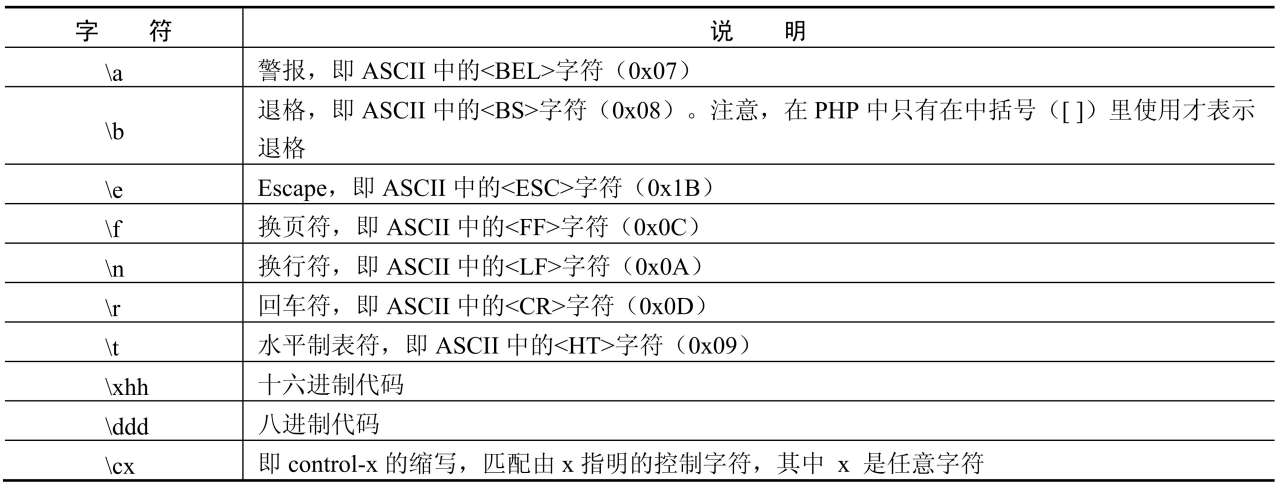
 反斜线可以将一些不可打印的字符显示出来,如表6.3所示。
反斜线可以将一些不可打印的字符显示出来,如表6.3所示。
表6.3 反斜线显示的不可打印字符
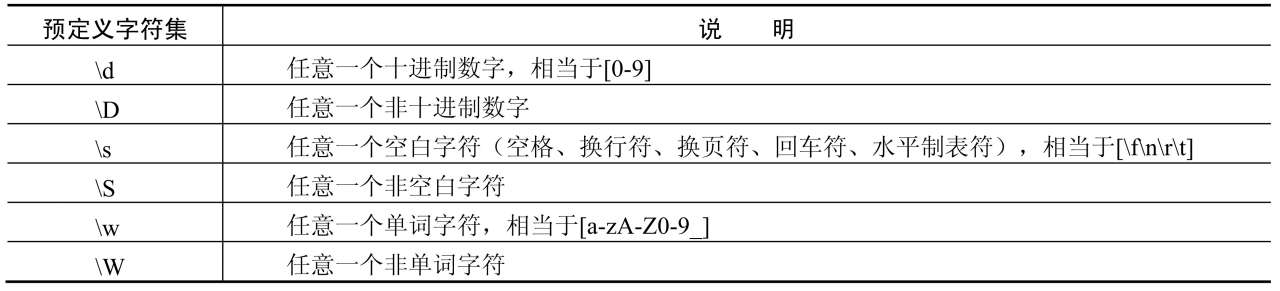
还可以指定预定义字符集,如表6.4所示。
表6.4 反斜线指定的预定义字符集
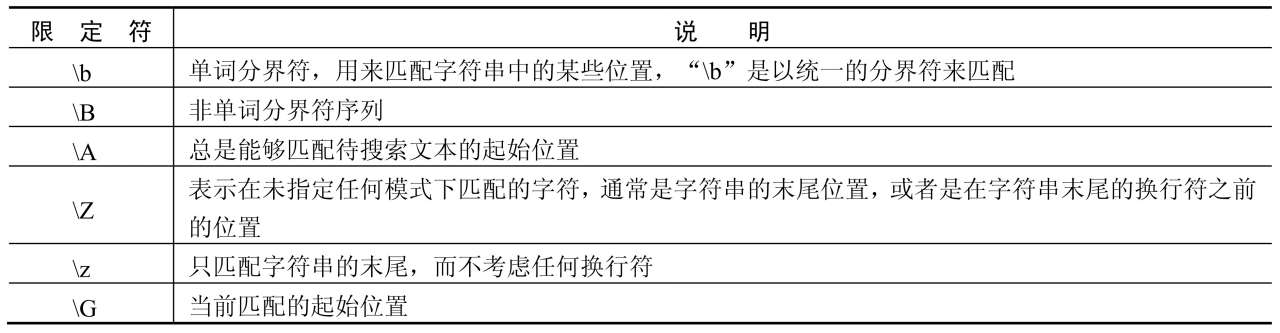
反斜线还有一种功能,就是定义断言,其中已经了解过了“b”“B”,其他如表6.5所示。
表6.5 反斜线定义断言的限定符
6.2.11 括号字符(())
通过6.2.4节的实例,相信读者已经对小括号的作用有了一定的了解。这里,再通过几个实例来巩固一下对小括号字符的印象。
小括号字符的第一个作用就是可以改变限定符的作用范围,如“|”“*”“^”等,来看下面的一个表达式。
(thir|four)th
这个表达式的意思是匹配单词thirth或fourth,如果不使用小括号,那么就变成了匹配单词thir和fourth了。
小括号的第二个作用是分组,也就是子表达式。如“(.[0-9]{1,3}){3}”,就是对分组“(.[0-9]{1,3})”进行重复操作。后面要学到的反向引用和分组有着直接的关系。
6.2.12 反向引用
反向引用,就是依靠子表达式的“记忆”功能来匹配连续出现的字串或字母。如匹配连续两个it,首先将单词it作为分组,然后在后面加上“1”即可。格式为:
(it)1
这就是反向引用最简单的格式。如果要匹配的字串不固定,那么就将括号内的字串写成一个正则表达式。如果使用了多个分组,那么可以用“1”“2”来表示每个分组(顺序是从左到右)。如:
([a-z])([A-Z])12
除了可以使用数字来表示分组外,还可以自己来指定分组名称。语法格式如下:
(? P<subname>…)
如果想要反向引用该分组,使用如下语法:
(? P=subname)
下面来重写一下表达式([a-z])([A-Z])12。为这两个分组分别命名,并反向引用它们。正则表达式如下:
(? P<fir>[a-z])(? P<sec>[A-Z])(? P=fir)(? P=sec)
反向引用的知识还可以参考6.3.4节。
6.2.13 模式修饰符
模式修饰符的作用是设定模式,也就是规定正则表达式应该如何解释和应用。不同的语言都有自己的模式设置,PHP中的主要模式如表6.6所示。
表6.6 模式修饰符

模式修饰符既可以写在正则表达式的外面,也可以写在表达式内。如忽略大小写模式,可以写为“/tm/i”“(? i)tm(? -i)”“(? i:tm)”3种格式。



发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。