
16.7 数据表记录的查询操作
视频讲解:光盘TMlx1611 数据表记录的查询操作.mp4
要从数据库中把数据查询出来,就要用到数据查询命令select。select命令是最常用的查询命令。
语法格式如下:
select selection_list --要查询的内容,选择哪些列 from table_list --指定数据表 where primary_constraint --查询时需要满足的条件,行必须满足的条件 group by grouping_columns --如何对结果进行分组 order by sorting_cloumns --如何对结果进行排序 having secondary_constraint --查询时满足的第二个条件 limit count --限定输出的查询结果
这就是select查询语句的语法,下面对它的参数进行详细的讲解。
1.selection_list
设置查询内容。如果要查询表中所有列,可以将其设置为“*”;如果要查询表中某一列或多列,则直接输入列名,并以“, ”为分隔符。
例如,查询tb_mrbook数据表中所有列与查询id和bookname列的代码如下:
select*from tb_mrbook; //查询数据表中所有数据 select id, bookname from tb_mrbook; //查询数据表中id和bookname列的数据
2.table_list
指定查询的数据表。即可以从一个数据表中查询,也可以从多个数据表中进行查询,多个数据表之间用“, ”进行分隔,并且通过where子句使用连接运算来确定表之间的联系。
例如,从tb_mrbook和tb_bookinfo数据表中查询bookname='PHP自学视频教程’的id编号、书名、作者和价格,其代码如下:
select tb_mrbook.id, tb_mrbook.bookname, -> author, price from tb_mrbook, tb_bookinfo -> where tb_mrbook.bookname = tb_bookinfo.bookname and -> tb_bookinfo.bookname = 'php自学视频教程’;
在上面的SQL语句中,因为两个表都有id字段和bookname字段,为了告诉服务器要显示的是哪个表中的字段信息,要加上前缀。语法如下:
表名.字段名
tb_mrbook.bookname = tb_bookinfo.bookname将表tb_mrbook和tb_bookinfo连接起来,叫作等同连接;如果不使用tb_mrbook.bookname = tb_bookinfo.bookname,那么产生的结果将是两个表的笛卡儿积,叫作全连接。
3.where条件语句
在使用查询语句时,如要从很多的记录中查询出想要的记录,就需要一个查询的条件。只有设定了查询的条件,查询才有实际的意义。设定查询条件应用的是where子句。
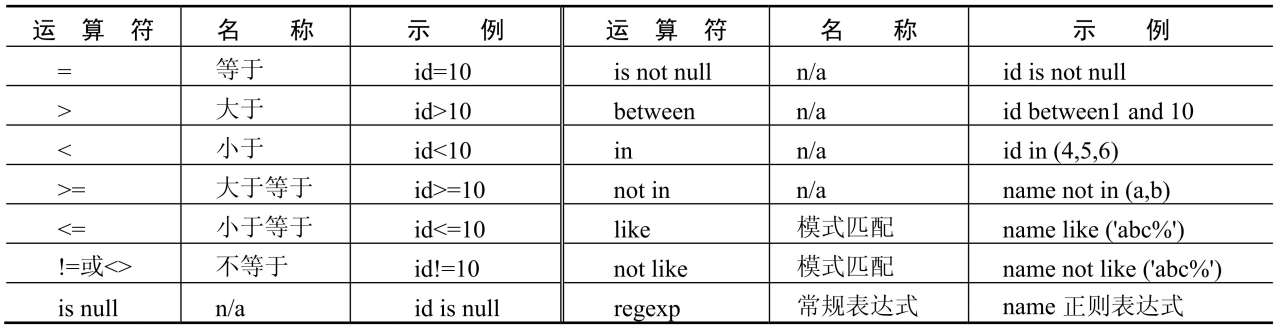
where子句的功能非常强大,通过它可以实现很多复杂的条件查询。在使用where子句时,需要使用一些比较运算符,常用的比较运算符如表16.9所示。
表16.9中列举的是where子句常用的比较运算符,示例中的id是记录的编号,name是表中的用户名。
例如,应用where子句,查询tb_mrbook表,条件是type(类别)为PHP的所有图书,代码如下:
select * from tb_mrbook where type = 'PHP';
表16.9 常用的where子句比较运算符
4.distinct
使用distinct关键字,可以去除结果中重复的行。
例如,查询tb_mrbook表,并在结果中去掉类型字段type中的重复数据,代码如下:
select distinct type from tb_mrbook;
5.order by
使用order by可以对查询的结果进行升序和降序(desc)排列,在默认情况下,order by按升序输出结果。如果要按降序排列,可以使用desc来实现。
对含有NULL值的列进行排序时,如果是按升序排列,NULL值将出现在最前面;如果是按降序排列,NULL值将出现在最后。
例如,查询tb_mrbook表中的所有信息,按照id进行降序排列,并且只显示五条记录。其代码如下:
select * from tb_mrbook order by id desc limit 5;
6.like
like属于较常用的比较运算符,通过它可以实现模糊查询。它有两种通配符:“%”和下划线“_”。
“%”可以匹配一个或多个字符,而“_”只匹配一个字符。
例如,查找所有书名(bookname字段)包含PHP的图书,代码如下:
select * from tb_mrbook where bookname like('%PHP%');
说明
无论是一个英文字符还是中文字符都算做一个字符,在这一点上英文字母和中文没有什么区别。
7.concat()函数
使用concat()函数可以联合多个字段,构成一个总的字符串。
例如,把tb_mrbook表中的书名(bookname)和价格(price)合并到一起,构成一个新的字符串。代码如下:
select id, concat(bookname, ":", price) as info, type from tb_mrbook;
其中,合并后的字段名为concat()函数形成的表达式“bookname:price”,看上去十分复杂,通过as关键字给合并字段取一个别名,这样看上去就清晰了。
8.limit
limit子句可以对查询结果的记录条数进行限定,控制它输出的行数。
例如,查询tb_mrbook表,按照图书价格升序排列,显示10条记录,代码如下:
select * from tb_mrbook order by price asc limit 10;
使用limit还可以从查询结果的中间部分取值。首先要定义两个参数,参数1是开始读取的第一条记录的编号(在查询结果中,第一个结果的记录编号是0,而不是1);参数2是要查询记录的个数。
例如,查询tb_mrbook表,从第3条记录开始,查询6条记录,代码如下:
select * from tb_mrbook limit 2,6;
9.使用函数和表达式
在mysql中,还可以使用表达式来计算各列的值,作为输出结果。表达式还可以包含一些函数。
例如,计算tb_mrbook表中各类图书的总价格,代码如下:
select sum(price) as totalprice, type from tb_mrbook group by type;
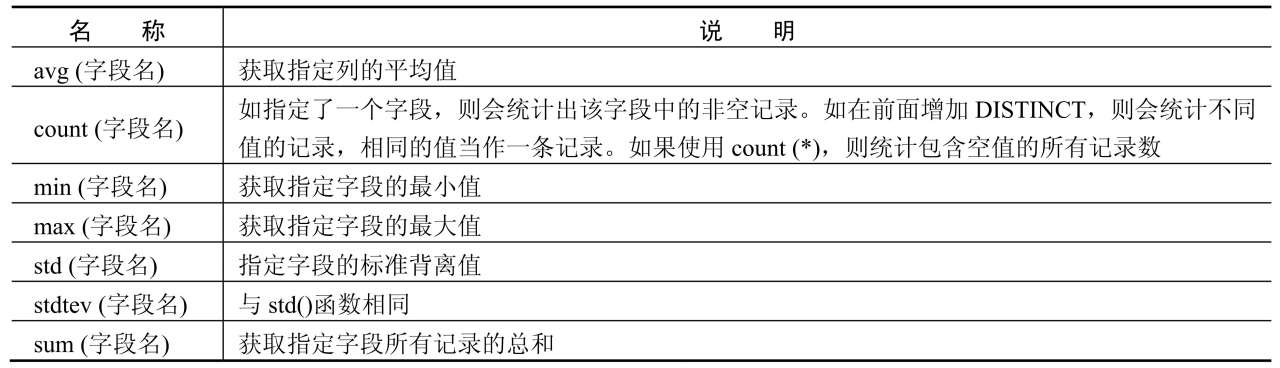
在对MySQL数据库进行操作时,有时需要对数据库中的记录进行统计,例如求平均值、最小值、最大值等,这时可以使用MySQL中的统计函数,其常用的统计函数如表16.10所示。
表16.10 MySQL中常用的统计函数
除了使用函数之外,还可以使用算术运算符、字符串运算符以及逻辑运算符来构成表达式。
例如,可以计算图书打九折之后的价格,代码如下:
select *, (price * 0.9) as '90%' from tb_mrbook;
10.group by
通过group by子句可以将数据划分到不同的组中,实现对记录进行分组查询。在查询时,所查询的列必须包含在分组的列中,目的是使查询到的数据没有矛盾。在与avg()函数或sum()函数一起使用时,group by子句能发挥最大作用。
例如,查询tb_mrbook表,按照type进行分组,求每类图书的平均价格,代码如下:
select avg(price), type from tb_mrbook group by type;
11.使用having子句设定第二个查询条件
having子句通常和group by子句一起使用。在对数据结果进行分组查询和统计之后,还可以使用having子句来对查询的结果进行进一步的筛选。having子句和where子句都用于指定查询条件,不同的是where子句在分组查询之前应用,而having子句在分组查询之后应用,而且having子句中还可以包含统计函数。
例如,计算tb_mrbook表中各类图书的平均价格,并筛选出图书的平均价格大于60的记录,代码如下:
select avg(price), type from tb_mrbook group by type having avg(price)>60;



发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。